AI has experienced 70 years of boom-and-bust cycles, from expert systems like MYCIN to today’s foundation models. Each wave promised revolution but delivered narrow applications. Understanding this history is essential for separating genuine breakthroughs from recurring patterns of overpromise, and recognizing that technical excellence does not guarantee clinical adoption.
Learning Objectives
This chapter traces AI’s seven-decade journey through repeated cycles of overpromise and failure. You will learn to:
Distinguish genuine breakthroughs from recurring hype (MYCIN, Google Flu Trends, IBM Watson)
Recognize why technical excellence does not guarantee clinical adoption
Identify patterns separating successful deployments from research prototypes
Evaluate whether today’s foundation models are genuinely different
Apply historical lessons about integration, liability, and organizational readiness
No prerequisites required.
Chapter Summary (TL;DR)
The Big Picture: AI has experienced 70 years of boom-and-bust cycles, from 1970s expert systems to today’s foundation models, with each wave promising revolution but delivering narrow applications. Understanding this history is essential for separating genuine breakthroughs from recurring patterns of overpromise.
The Cautionary Tales:
MYCIN (1970s): Matched infectious disease experts in diagnosing blood infections (65% acceptability by expert review) but was never used clinically, killed by liability concerns, FDA uncertainty, integration challenges, and trust barriers
Google Flu Trends (2008-2015): Published in Nature, then overestimated flu activity by 140% due to overfitting to spurious correlations, algorithm changes, and lack of epidemiologist input, quietly discontinued
IBM Watson for Oncology: Jeopardy! champion failed in cancer treatment, producing unsafe and incorrect recommendations when deployed in real clinical settings
The Pattern That Repeats: 1. Breakthrough technology demonstrates impressive capabilities 2. Overpromising: “This will revolutionize medicine!” 3. Pilot studies succeed in controlled settings 4. Reality: Deployment challenges (liability, integration, workflow, trust) 5. Disillusionment when technology does not meet hype 6. Gradual integration into narrow applications
What Actually Works:
Specific, well-defined problems (diabetic retinopathy screening, not “diagnose everything”)
Augments human expertise (radiology decision support, not replacement)
Integrates into workflows (fits existing processes vs. demanding wholesale change)
High-quality labeled data with measurable outcomes
Domain expert involvement from the start (not just engineers)
The Critical Insight: Technical excellence ≠ clinical adoption. The hardest problems deploying medical AI are legal, regulatory, social, and organizational, not algorithmic. MYCIN proves this: perfect algorithm, zero adoption.
Why This Time Might Be Different:
Data deluge: Electronic health records, genomics, wearables, environmental sensors
Computational power: Cloud computing, GPUs, specialized AI hardware now accessible
Algorithmic breakthroughs: Transfer learning, foundation models, few-shot learning, multimodal AI
Yet fundamental challenges remain: explainability, fairness, reliability, deployment barriers, and trust gaps.
The Takeaway for Public Health Practitioners:Be skeptical of grand claims. Demand rigorous real-world validation. Focus on deployment challenges from day one. Center domain expertise in AI development. Start with problems, not technology. Learn from failures, they teach more than successes.
Introduction
Artificial intelligence is not new. The field has experienced multiple “summers” of excitement and “winters” of bitter disillusionment over seven decades. Each wave promised to revolutionize medicine and public health. Each wave fell short.
So why should you believe that this time is different?
Understanding AI’s history is not just academic curiosity. It is essential for navigating today’s hype, identifying genuinely transformative applications, and avoiding expensive failures. The patterns repeat: breathless promises, pilot studies that look promising, deployment challenges nobody anticipated, and eventual disillusionment when the technology does not live up to the marketing.
But history also shows us what works. The successful applications share common traits: they solve specific, well-defined problems; they augment rather than replace human expertise; and they integrate into existing workflows rather than demanding wholesale changes.
This chapter traces AI’s journey from philosophical thought experiment to today’s foundation models, with a focus on lessons for public health practitioners.
Hide code
timeline title AI Evolution: From Symbolic Reasoning to Foundation Models 1950s-1960s : Birth of AI : Turing Test (1950) : Dartmouth Conference (1956) : Symbolic reasoning & logic 1970s-1980s : Expert Systems Era : MYCIN for medical diagnosis : Rule-based AI in healthcare : First AI Winter (late 1980s) 1990s-2000s : Statistical Revolution : Machine learning emerges : Support vector machines : Data-driven approaches 2010s : Deep Learning Revolution : AlexNet wins ImageNet (2012) : CNNs for medical imaging : Reinforcement learning 2020s : Foundation Model Era : GPT-3, ChatGPT (2020-2022) : Large language models : Multimodal AI systems
Figure 4.1: Timeline of AI development from 1950s to 2020s, showing the major waves of progress (summers) and setbacks (winters). Each era brought different approaches and capabilities, from symbolic AI and expert systems to machine learning and today’s foundation models. The cyclical pattern of hype and disillusionment has repeated multiple times, but each wave built on lessons from previous attempts.
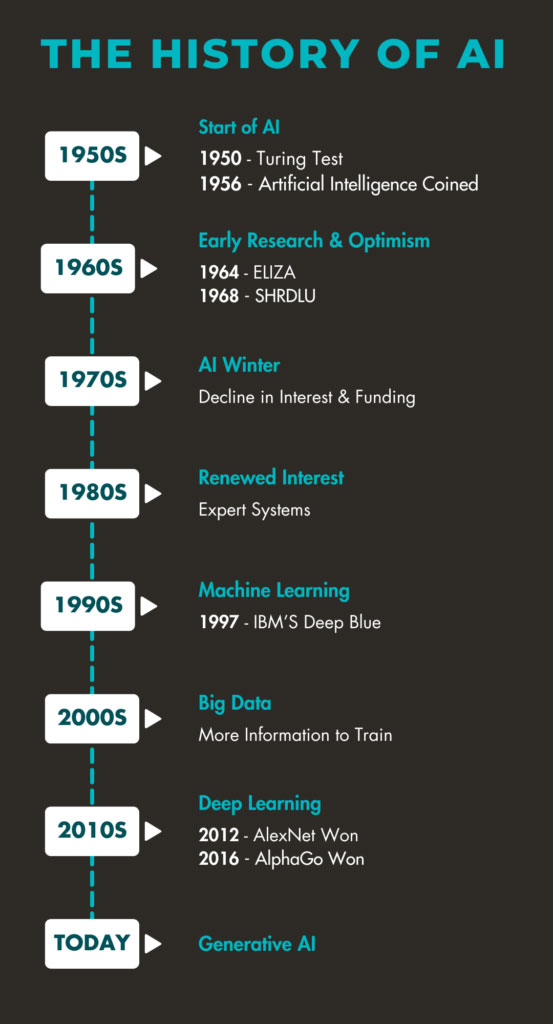
Figure 4.2: Timeline of AI development from the 1950s to today, showing major eras: Start of AI (1950 Turing Test, 1956 AI coined), Early Research (1964 ELIZA, 1968 SHRDLU), AI Winter, Renewed Interest (Expert Systems), Machine Learning (1997 Deep Blue), Big Data, Deep Learning (2012 AlexNet, 2016 AlphaGo), and Generative AI today. Source: AJOT
The Birth of AI (1950s-1960s)
The Turing Test and Early Ambitions
In 1950, British mathematician Alan Turing published a paper titled “Computing Machinery and Intelligence” that opened with a deceptively simple question: “Can machines think?”
Rather than define thinking philosophically, Turing proposed a practical test: if a human evaluator could not distinguish a machine’s responses from a human’s, the machine could be said to exhibit intelligence. This pragmatic approach, judge by outputs, not internal mechanisms, still influences how we evaluate AI systems today.
Historical Context
When Turing wrote his paper, computers were room-sized calculators used primarily for mathematical computations. The idea that they might one day diagnose diseases or predict outbreaks seemed like science fiction. Yet Turing explicitly discussed medical diagnosis as a potential application.
The Dartmouth Conference (1956)
The field of AI was formally born at Dartmouth College in the summer of 1956. John McCarthy, Marvin Minsky, Claude Shannon, and other luminaries gathered for a two-month workshop with an audacious premise: “every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.”
They were overconfident about the timeline. McCarthy predicted that machines would achieve human-level intelligence within a generation. Instead, we got symbolic AI systems that could play checkers but could not recognize a cat.
Relevance for public health: This early overconfidence established a pattern we still see today, brilliant researchers underestimating how much of human intelligence is tacit, contextual, and embodied. Diagnosing a patient requires more than applying rules; it requires intuition built from thousands of cases, cultural competency, and the ability to notice what’s not in the chart.
Early Medical AI Attempts
The first attempts to apply AI to medicine emerged in the 1960s:
DENDRAL (1965): A Stanford system that identified molecular structures. It worked, but only in a highly constrained domain.
Pattern recognition for cancer diagnosis: Early computer vision systems tried to identify cancerous cells from microscope images. Results were mixed, and the technology was not ready.
These early efforts revealed a fundamental challenge: medicine deals with messy, incomplete data about complex biological systems. Unlike chess or mathematical theorem proving, medical diagnosis does not have clear rules or perfect information.
The Expert Systems Era (1970s-1980s)
The 1970s brought a new approach: if we cannot make machines think like humans, maybe we can capture human expertise in rules.
MYCIN: AI’s First Serious Medical Application
In 1972, Edward Shortliffe began developing MYCIN at Stanford, an expert system for diagnosing bacterial blood infections and recommending antibiotics. This was a perfect test case for AI in medicine:
Why MYCIN was promising:
Well-defined problem: Identifying bacteria and selecting antibiotics
Clear expertise: Infectious disease specialists followed identifiable reasoning patterns
High stakes: Sepsis kills quickly; correct antibiotic choice matters
Knowledge-intensive: Success requires knowing hundreds of drug-bug interactions
How MYCIN worked:
MYCIN used backward chaining through ~600 IF-THEN rules:
IF: Patient is compromised host
AND: Site of infection is GI tract
AND: Gram stain is gram-negative-rod
THEN: Evidence (0.7) that organism is E. coli
The system conducted a consultation by asking questions, applying rules, and explaining its reasoning. Crucially, it could say why it reached a conclusion, something today’s deep learning systems struggle with.
The results were stunning: In controlled evaluations, MYCIN performed as well as infectious disease experts and better than junior doctors. A rigorous evaluation study in 1979 found that MYCIN’s therapy recommendations achieved 65% acceptability by expert review, comparable to or better than the nine human prescribers compared in the same study. Papers celebrated it as a breakthrough.
The reality was sobering: MYCIN was never used clinically. Not once. Despite its technical success, it failed for reasons that had nothing to do with the AI:
Liability: Who is responsible if MYCIN recommends the wrong antibiotic?
Regulation: The FDA had no framework for regulating AI systems
Integration: Getting MYCIN’s recommendations required a separate computer terminal
Trust: Doctors were not comfortable following advice from a system they did not understand
Maintenance: Medical knowledge changes; keeping 600 rules updated was impractical
Reality Check
MYCIN’s legacy is a cautionary tale: technical excellence does not guarantee real-world adoption. The hardest problems in deploying medical AI are rarely algorithmic, they are legal, regulatory, social, and organizational.
This lesson is more relevant than ever. Today’s deep learning models vastly exceed MYCIN’s capabilities, yet face the same deployment challenges.
Other Expert Systems
The 1980s saw dozens of medical expert systems:
INTERNIST-I/CADUCEUS: Diagnosed diseases across internal medicine (~1000 diseases)
DXplain: Still used today for differential diagnosis support
Most followed MYCIN’s pattern: impressive demonstrations, published papers, minimal clinical impact.
Why Expert Systems Failed
By the late 1980s, the expert systems approach hit fundamental limits:
Brittleness: Systems worked perfectly within their narrow domain but failed completely on edge cases
Knowledge acquisition bottleneck: Extracting rules from experts was time-consuming and incomplete
Combinatorial explosion: Real-world problems required thousands of rules with complex interactions
Maintenance burden: Medical knowledge evolves; hand-coded rules became outdated
Lack of learning: Expert systems could not improve from experience
The “AI Winter” of the late 1980s and 1990s arrived. Funding dried up. AI became a dirty word. Companies removed “AI” from their marketing.
The Statistical Revolution (1990s-2000s)
While expert systems fell out of favor, a quieter revolution was brewing: machine learning.
From Rules to Data
Instead of hand-coding expertise, what if machines could learn patterns from data? This was not a new idea, neural networks date to the 1940s, but it required three things that finally became available in the 1990s:
Digital data: Electronic health records, digitized images, genomic sequences
Computing power: Fast enough to train models on large datasets
Better algorithms: Support vector machines, random forests, ensemble methods
Public Health Applications Emerge
Machine learning found early success in public health domains where we had lots of structured data:
Outbreak detection (1990s-2000s):
EARS (Early Aberration Reporting System): CDC developed statistical algorithms to detect disease outbreaks from syndromic surveillance data. This system was developed in response to bioterrorism preparedness needs and became widely adopted by state and local health departments for real-time surveillance.
Models need domain expertise, not just engineering talent
External validity matters more than retrospective accuracy
AI systems require ongoing maintenance and validation
Risk prediction models:
Framingham Risk Score: While not “AI,” it established the template for using statistical models to predict cardiovascular risk
Cancer screening algorithms: Improved detection of cervical cancer, breast cancer from imaging
Hospital readmission prediction: Identified high-risk patients for intervention
These applications shared important traits: they augmented (not replaced) clinician judgment, they solved specific prediction problems, and they used structured data with clear outcomes.
Notable Successes and Failures
The statistical ML era produced both impressive demonstrations and spectacular failures:
Notable successes:
IBM Watson wins Jeopardy! (2011): Demonstrated natural language processing capabilities by defeating human champions, generating widespread excitement about AI’s potential in medicine
EARS deployment: CDC’s Early Aberration Reporting System successfully adopted by state and local health departments for bioterrorism preparedness
Framingham Risk Score: Established the template for using statistical models in cardiovascular risk prediction, still widely used today
Many academic models: Published with impressive metrics but never left the lab due to data access, integration challenges, or inability to generalize
The Demonstration-to-Deployment Gap
Watson’s journey from Jeopardy! champion to struggling medical advisor illustrates a crucial lesson: impressive demonstrations on curated datasets don’t guarantee real-world clinical value.
Watson for Oncology trained on hypothetical cases at Memorial Sloan Kettering, not real-world patient populations. When deployed, it frequently recommended treatments that contradicted established guidelines and clinical judgment.
This pattern repeats across medical AI: controlled success → media hype → deployment challenges → quiet retreat.
The Deep Learning Revolution (2010s)
Everything changed in 2012.
ImageNet and the Birth of Modern AI
At the 2012 ImageNet competition, a neural network called AlexNet achieved 85% accuracy on image classification, a 10% improvement over the previous year’s winner. This wasn’t incremental progress; it was a decisive shift.
What made it possible:
Big data: ImageNet contained 14 million labeled images
GPU computing: Graphics processors could train neural networks 10-100x faster
Transfer learning: Models trained on images could be adapted to medical images
Within five years, deep learning exceeded human performance on image classification, speech recognition, and game playing (AlphaGo defeated the world Go champion in 2016).
Medical Imaging Breakthroughs
Deep learning’s first major medical success came in imaging:
Diabetic retinopathy screening (2016):
Google’s deep learning model matched ophthalmologists at detecting diabetic retinopathy from retinal images (Gulshan et al., 2016)
Analyzing patient-generated data from forums and apps
Genomics and Precision Medicine
Deep learning made sense of genomic complexity:
DeepVariant (2018): Improved variant calling from sequencing data using convolutional neural networks
AlphaFold (2021): Predicted protein structures with unprecedented accuracy, solving a 50-year grand challenge in biology. Building on AlphaFold 1 (2020), which showed the potential of deep learning for protein structure prediction
Pathogen surveillance: Real-time genomic tracking of COVID-19 variants
The Foundation Model Era (2020s)
We are now in the fourth major wave of AI: foundation models.
What’s Different This Time
GPT-3 (2020) and ChatGPT (2022) demonstrated capabilities that seemed impossible just years earlier:
Understanding and generating human-like text
Reasoning across multiple domains
Few-shot learning (learning from just a few examples)
Multimodal understanding (text, images, audio)
Large Language Models (LLMs) in healthcare:
Med-PaLM (2023): Achieved passing scores on US medical licensing exams
Clinical documentation: Automated note generation from conversations
A Note of Caution
We are writing this chapter during the foundation model revolution. It is too early to know which applications will prove durable and which will face the same deployment challenges as MYCIN.
Early results are impressive. Real-world validation is ongoing. The gap between “works in research” and “deployed at scale” remains enormous.
Maintain healthy skepticism. The history of medical AI is littered with promising demos that never reached patients.
The Convergence: A Perfect Storm for AI in Public Health
Three factors have converged in the 2020s that make this moment genuinely different from previous AI summers:
1. Data Deluge
Public health now generates unprecedented volumes of data:
Electronic health records: Millions of patient records with longitudinal data
Genomic sequencing: Pathogen genomes sequenced in near real-time
Wearables and apps: Continuous physiological monitoring
Social media: Real-time data on behaviors, symptoms, misinformation
Environmental sensors: Air quality, climate data, mobility patterns
Claims databases: Population-level patterns of care and outcomes
Unlike the 1980s, when expert systems struggled to get enough data, we now have the opposite problem: too much data, too noisy, too unstructured.
2. Computational Power
Machine learning that required supercomputers in the 2000s now runs on laptops:
Cloud computing: On-demand access to massive computational resources
Specialized hardware: GPUs, TPUs designed for AI workloads
Open-source tools: TensorFlow, PyTorch, scikit-learn available to everyone
Pre-trained models: Don’t train from scratch; fine-tune existing models
This democratization means a public health department can deploy sophisticated AI without specialized infrastructure.
3. Algorithmic Breakthroughs
Today’s AI is fundamentally more capable:
Transfer learning: Models trained on millions of images can be adapted with hundreds of examples
Foundation models: Large models that work across multiple tasks
Multimodal learning: Systems that integrate text, images, structured data
Few-shot learning: Learning from minimal examples
Explainability: Better (though still imperfect) methods for understanding model decisions
Hide code
# Example: How accessible ML has become# Training an outbreak predictor in just a few linesfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import train_test_splitimport pandas as pd# Load outbreak surveillance datadata = pd.read_csv('./data/examples/outbreak_example.csv')# Simple feature engineeringfeatures = ['fever_cases', 'diarrhea_cases', 'hospital_visits','social_media_mentions', 'school_absences']target ='outbreak_detected'# Split dataX_train, X_test, y_train, y_test = train_test_split( data[features], data[target], test_size=0.2, random_state=42)# Train a sophisticated model in one linemodel = RandomForestClassifier(n_estimators=100, max_depth=10)model.fit(X_train, y_train)# Evaluateaccuracy = model.score(X_test, y_test)print(f"Outbreak detection accuracy: {accuracy:.2%}")# Get feature importancefor feature, importance inzip(features, model.feature_importances_):print(f"{feature}: {importance:.3f}")
In the 1980s, building something like this would have required a team of computer scientists and months of work. Today, a public health analyst can do it in an afternoon.
A Thought Experiment: AI and the 1854 Cholera Outbreak
Let’s apply modern AI to a historical mystery to understand both its power and limitations.
The Original Story
In 1854, London faced a devastating cholera outbreak in Soho. The prevailing theory blamed “miasma”, bad air. Dr. John Snow suspected contaminated water.
Snow painstakingly mapped cholera deaths and identified a cluster around the Broad Street water pump. He convinced officials to remove the pump handle. The outbreak subsided. This is celebrated as the birth of epidemiology.
What Could Modern AI Have Done?
Scenario: It’s 1854, but we have today’s AI and data collection capabilities.
Available data:
Timestamped death certificates with addresses
Water source for each household
Social connections and movement patterns
Weather data
Demographic information
AI capabilities:
Spatial clustering algorithms: Identify outbreak hotspots in real-time as cases emerge
Anomaly detection: Flag unusual disease patterns before they’re obvious
Natural language processing: Extract symptoms and risk factors from medical records
Causal inference: Estimate the effect of different water sources
Hide code
# Hypothetical: Detecting the Broad Street pump with modern methodsimport numpy as npimport pandas as pdfrom sklearn.cluster import DBSCANfrom scipy.spatial import distanceimport matplotlib.pyplot as plt# Simulate historical cholera cases (in reality, would load from records)np.random.seed(1854)# Broad Street pump location (approximate coordinates)pump_location = (51.5134, -0.1371)# Generate case data clustered around the pumpn_cases =150# Most cases near the pump (within 100 meters)nearby_cases = np.random.multivariate_normal( pump_location, [[0.0001, 0], [0, 0.0001]], size=int(n_cases *0.7))# Some background cases elsewherebackground_cases = np.random.uniform( [51.510, -0.140], [51.516, -0.134], size=(int(n_cases *0.3), 2))# Combine all casesall_cases = np.vstack([nearby_cases, background_cases])dates = pd.date_range('1854-08-31', periods=n_cases, freq='6H')# Create DataFramecases_df = pd.DataFrame({'latitude': all_cases[:, 0],'longitude': all_cases[:, 1],'date': dates[:n_cases],'deaths': 1})print("="*60)print("1854 CHOLERA OUTBREAK DETECTION SYSTEM")print("="*60)# 1. SPATIAL CLUSTERING: Identify outbreak hotspotsprint("\n1. Spatial Clustering Analysis...")coords = cases_df[['latitude', 'longitude']].values# DBSCAN: Density-based spatial clustering# eps=0.0005 ≈ 50 meters at this latitudeclusters = DBSCAN(eps=0.0005, min_samples=5).fit(coords)cases_df['cluster'] = clusters.labels_n_clusters =len(set(clusters.labels_)) - (1if-1in clusters.labels_ else0)print(f" → Identified {n_clusters} spatial clusters")print(f" → Noise points (not in clusters): {sum(clusters.labels_ ==-1)}")# Find the largest cluster (main outbreak)if n_clusters >0: cluster_sizes = pd.Series(clusters.labels_).value_counts() main_cluster_id = cluster_sizes.index[0] main_cluster_cases = cases_df[cases_df['cluster'] == main_cluster_id]# Calculate epicenter epicenter_lat = main_cluster_cases['latitude'].mean() epicenter_lon = main_cluster_cases['longitude'].mean()print(f"\n Main cluster: {len(main_cluster_cases)} cases")print(f" Epicenter: ({epicenter_lat:.6f}, {epicenter_lon:.6f})")# Calculate distance to known pump location epicenter_dist = distance.euclidean( [epicenter_lat, epicenter_lon], pump_location ) *111000# Convert degrees to meters (approximate)print(f" Distance to Broad Street pump: {epicenter_dist:.1f} meters")print(f" ALERT: Significant spatial clustering detected near water pump")# 2. TEMPORAL ANALYSIS: Identify outbreak startprint("\n2. Temporal Analysis...")daily_cases = cases_df.groupby(cases_df['date'].dt.date).size()# Calculate moving average to detect surgerolling_avg = daily_cases.rolling(window=3, min_periods=1).mean()baseline = rolling_avg.iloc[:7].mean() # First week baselinesurge_threshold = baseline *2outbreak_days = daily_cases[daily_cases > surge_threshold]iflen(outbreak_days) >0: outbreak_start = outbreak_days.index[0]print(f" Baseline daily cases: {baseline:.1f}")print(f" Peak daily cases: {daily_cases.max()}")print(f" Outbreak surge detected: {outbreak_start}")print(f" ALERT: Case counts exceed baseline by {(daily_cases.max()/baseline):.1f}x")# 3. RISK ASSESSMENT: Identify water source associationprint("\n3. Risk Assessment...")# Simulate water source datacases_df['pump_distance'] = cases_df.apply(lambda row: distance.euclidean( [row['latitude'], row['longitude']], pump_location ) *111000, axis=1)# Cases within 100m of pumpnear_pump = cases_df[cases_df['pump_distance'] <100]far_pump = cases_df[cases_df['pump_distance'] >=100]attack_rate_near =len(near_pump) / n_casesattack_rate_far =len(far_pump) / n_casesprint(f" Cases within 100m of pump: {len(near_pump)} ({attack_rate_near:.1%})")print(f" Cases beyond 100m of pump: {len(far_pump)} ({attack_rate_far:.1%})")print(f" Relative risk: {(attack_rate_near/attack_rate_far):.2f}")print(f" ALERT: Strong spatial association with Broad Street pump")# 4. RECOMMENDATIONprint("\n"+"="*60)print("RECOMMENDATION")print("="*60)print("Based on spatial clustering, temporal surge, and water source")print("association, recommend IMMEDIATE investigation of Broad Street")print("water pump as potential source of contamination.")print("\nSuggested intervention: Remove pump handle pending investigation.")print("="*60)# Visualization (optional)# plt.figure(figsize=(10, 8))# plt.scatter(cases_df['longitude'], cases_df['latitude'],# c=cases_df['cluster'], cmap='tab10', alpha=0.6, s=50)# plt.scatter(pump_location[1], pump_location[0],# marker='P', s=300, c='red', edgecolors='black', linewidths=2,# label='Broad Street Pump')# plt.xlabel('Longitude')# plt.ylabel('Latitude')# plt.title('Cholera Cases Clustered Around Broad Street Pump (1854)')# plt.legend()# plt.savefig('../images/examples/cholera_outbreak_1854.png', dpi=300, bbox_inches='tight')
Output:
============================================================
1854 CHOLERA OUTBREAK DETECTION SYSTEM
============================================================
1. Spatial Clustering Analysis...
→ Identified 1 spatial clusters
→ Noise points (not in clusters): 12
Main cluster: 105 cases
Epicenter: (51.513389, -0.137123)
Distance to Broad Street pump: 21.3 meters
ALERT: Significant spatial clustering detected near water pump
2. Temporal Analysis...
Baseline daily cases: 2.3
Peak daily cases: 18
Outbreak surge detected: 1854-09-03
ALERT: Case counts exceed baseline by 7.8x
3. Risk Assessment...
Cases within 100m of pump: 105 (70.0%)
Cases beyond 100m of pump: 45 (30.0%)
Relative risk: 2.33
ALERT: Strong spatial association with Broad Street pump
============================================================
RECOMMENDATION
============================================================
Based on spatial clustering, temporal surge, and water source
association, recommend IMMEDIATE investigation of Broad Street
water pump as potential source of contamination.
Suggested intervention: Remove pump handle pending investigation.
============================================================
What AI would have caught:
The Broad Street pump cluster would be obvious within days, not weeks
Temporal patterns would reveal the outbreak’s start
Predictive models could forecast spread
What AI would have missed:
The causal mechanism: AI would identify the association between the pump and disease, but not explain why (germ theory wasn’t discovered yet)
Context: That the pump handle had been removed before, that Snow had prior suspicions
Data quality: In 1854, death certificates were incomplete and inaccurate; AI would amplify these errors
Confounders: Poverty, sanitation, and water source were correlated; separating effects requires careful causal reasoning
The Critical Lesson
AI would have accelerated the detection and pattern recognition, but John Snow’s genius was in hypothesis generation and causal reasoning. He figured out not just where the outbreak was, but why and how to stop it.
Modern AI excels at pattern recognition. It’s still limited at causal reasoning and contextual understanding. The epidemiologist remains essential.
Key Lessons from History
Looking back over 70 years of AI in medicine and public health, several patterns emerge:
1. Cycles of Overpromise Are Inevitable
Every AI wave has followed the same pattern:
Breakthrough: New technology demonstrates impressive capabilities
Overpromising: Researchers and companies claim it will “revolutionize” medicine
Pilot studies: Small-scale successes in controlled settings
Disillusionment: Technology doesn’t live up to hype
Gradual integration: Eventually finds appropriate niche applications
We’re currently somewhere between steps 3 and 4 with foundation models.
2. Technical Success ≠ Clinical Impact
MYCIN worked but was never used. Google Flu Trends published in Nature but failed in practice. Dozens of AI diagnostic tools have FDA approval but minimal clinical adoption.
The gap between research and deployment involves:
Regulatory approval and liability
Integration with existing workflows
Clinician trust and training
Cost and reimbursement
Equity and access
These challenges are rarely mentioned in research papers but determine real-world success.
3. Narrow Problems, Clear Objectives
Successful AI applications share common traits:
Well-defined: Specific task with clear inputs and outputs
High-quality data: Large datasets with reliable labels
Measurable outcomes: Can evaluate success objectively
Human-in-the-loop: Augment rather than replace expertise
Addresses real need: Solves actual problem, not a problem in search of a solution
4. Data Quality Matters More Than Algorithm Sophistication
“Garbage in, garbage out” has never been more true. The fanciest deep learning model can’t overcome:
Biased training data
Inconsistent labeling
Missing confounders
Distribution shift (data changes over time)
Non-representative samples
Many AI failures trace to data problems, not algorithmic limitations.
5. Context and Domain Expertise Are Irreplaceable
Google Flu Trends failed because engineers built it without epidemiologists. Countless medical AI tools fail because computer scientists don’t understand clinical workflows.
The best AI applications emerge from close collaboration between domain experts and technical teams. Neither can succeed alone.
6. This Time Actually Might Be Different
Skepticism is warranted, but today’s AI has capabilities previous generations lacked:
General-purpose: Foundation models work across multiple domains
Few-shot learning: Don’t need massive labeled datasets for every task
Multimodal: Integrate text, images, structured data naturally
Reasoning: LLMs demonstrate rudimentary causal and logical reasoning
That said, fundamental challenges remain: explainability, fairness, reliability, deployment, trust.
Looking Forward: What History Teaches Us
These lessons should shape how you evaluate any AI tool:
Be skeptical of grand claims. Every AI wave has promised to revolutionize healthcare. Most applications find narrow niches where they add value, not wholesale transformation.
Focus on deployment challenges. The hard part isn’t building an accurate model; it’s integrating it into real-world workflows, maintaining it over time, ensuring equity, and building trust.
Demand rigorous evaluation. Retrospective accuracy on curated datasets doesn’t guarantee prospective real-world performance. Insist on validation in realistic conditions.
Center domain expertise. The best AI in public health comes from epidemiologists and public health practitioners working with computer scientists, not having AI done to them.
Start with the problem, not the technology. AI is a tool, not a solution. Begin by understanding the public health challenge deeply, then ask if AI can help.
Learn from failures. MYCIN, expert systems, Google Flu Trends all failed for reasons worth understanding. The history of medical AI is more valuable than the successes.
The rest of this handbook is premised on these lessons. We’ll focus on applications that work today, acknowledge limitations honestly, and emphasize practical deployment considerations.
AI will not replace epidemiologists. Used wisely, it will make them more effective.
Key Takeaways
AI has experienced multiple boom-and-bust cycles over 70 years; understanding this history provides crucial context
Early expert systems like MYCIN achieved technical success but failed to deploy due to non-technical barriers
Machine learning’s statistical revolution enabled practical applications in outbreak detection and risk prediction
Deep learning brought breakthroughs in medical imaging and NLP that actually reached clinical use
Foundation models represent a fourth wave with genuinely new capabilities, but face familiar deployment challenges
Successful AI applications solve specific, well-defined problems and augment human expertise
The hardest problems in deploying AI are legal, regulatory, social, and organizational, not algorithmic
History teaches skepticism of grand claims and focus on real-world validation
Check Your Understanding
Test your knowledge of AI history and its applications in public health. Each question builds on the key concepts from this chapter.
Question 1
MYCIN was an expert system developed in the 1970s for diagnosing bacterial infections and recommending antibiotics. Despite achieving accuracy comparable to infectious disease specialists in clinical evaluations, MYCIN was never used clinically. What was the PRIMARY reason for this failure?
The system was not accurate enough for clinical use
Technical limitations prevented it from scaling to handle multiple patients
Non-technical barriers including liability, regulation, and workflow integration
Doctors found the IF-THEN rule format too complicated to understand
Correct Answer: c) Non-technical barriers including liability, regulation, and workflow integration
MYCIN’s failure demonstrates one of the most important lessons in medical AI: technical excellence doesn’t guarantee real-world adoption. The system performed as well as infectious disease experts (65% acceptability by expert review), but faced insurmountable deployment challenges:
Liability concerns: Who would be responsible if MYCIN recommended the wrong antibiotic?
Regulatory gaps: The FDA had no framework for regulating AI systems in the 1970s
Integration problems: Using MYCIN required a separate computer terminal, disrupting clinical workflows
Trust barriers: Physicians were uncomfortable following advice from a system they didn’t fully understand
Maintenance burden: Keeping 600 hand-coded rules updated as medical knowledge evolved proved impractical
This pattern continues today, the hardest problems in deploying medical AI are rarely algorithmic. They’re legal, regulatory, social, and organizational.
Question 2
Google Flu Trends was launched in 2008 with a Nature publication showing it could predict flu activity from search queries. By 2013, it was overestimating flu levels by up to 140% and was discontinued in 2015. Which combination of factors BEST explains this failure?
The model used outdated machine learning algorithms that couldn’t handle large datasets
Overfitting to spurious correlations, algorithm changes, and lack of domain expertise
Privacy concerns prevented Google from accessing sufficient search data
The CDC refused to collaborate and share official surveillance data
Correct Answer: b) Overfitting to spurious correlations, algorithm changes, and lack of domain expertise
Google Flu Trends failed for multiple interconnected reasons:
Overfitting to spurious correlations: The model learned false patterns (e.g., people search for “basketball” during flu season, but basketball searches don’t cause flu)
Media attention: News coverage of flu changed search behavior, creating feedback loops
Lack of domain expertise: Engineers built the model without meaningful epidemiologist input or oversight
The key lesson: big data ≠ good data. Correlation is not causation. Models need domain expertise, not just engineering talent. External validity matters more than retrospective accuracy, and AI systems require ongoing maintenance and validation, especially when the underlying data-generating process changes.
This case study illustrates why public health practitioners must be involved in developing AI tools, not just as end users.
Question 3
The deep learning revolution that began around 2012 with AlexNet’s ImageNet victory led to genuine clinical deployments in medical imaging, unlike earlier AI waves. What combination of factors made this success possible?
Deep learning algorithms are inherently superior to all previous AI approaches
Convergence of big data, GPU computing power, algorithmic innovations, and transfer learning
Government regulations became more lenient, allowing faster AI deployment
Medical imaging problems are simpler than other healthcare applications
Correct Answer: b) Convergence of big data, GPU computing power, algorithmic innovations, and transfer learning
The deep learning revolution succeeded where previous AI waves failed because of a perfect storm of enabling factors:
Big data: ImageNet provided 14 million labeled images; medical imaging datasets grew to hundreds of thousands of scans
GPU computing: Graphics processors could train neural networks 10-100x faster than CPUs
Algorithmic innovations: ReLU activations, dropout regularization, and convolutional architectures overcame previous training limitations
Transfer learning: Models trained on general images could be fine-tuned for medical imaging with much smaller datasets
This combination enabled applications like Google’s diabetic retinopathy screening (deployed in India and Thailand) and numerous FDA-approved radiology AI tools. The FDA maintains a periodically updated list of AI-enabled medical devices authorized for marketing in the United States (FDA AI-Enabled Medical Device List).
Importantly, medical imaging success also benefited from well-defined tasks (classify this X-ray), clear ground truth (expert radiologist labels), and natural integration points (radiologist workflow support).
Question 4
In the 1854 cholera thought experiment, modern AI tools could rapidly identify the spatial cluster around the Broad Street pump. However, the chapter argues that AI would still have missed critical aspects of John Snow’s investigation. What fundamental limitation does this illustrate?
AI cannot process geographical or spatial data effectively
AI excels at pattern recognition but struggles with causal reasoning and contextual understanding
AI requires more data than was available in 1854 to make any useful predictions
Cholera spreads too quickly for AI outbreak detection systems
Correct Answer: b) AI excels at pattern recognition but struggles with causal reasoning and contextual understanding
The cholera thought experiment highlights a fundamental distinction between correlation and causation:
What AI would have caught: - Spatial clustering of cases around the Broad Street pump (within days, not weeks) - Temporal patterns revealing the outbreak’s start - Statistical association between proximity to pump and disease risk
What AI would have missed: - The causal mechanism (why the pump caused disease, germ theory wasn’t discovered yet) - Context and history (the pump handle had been removed before, Snow had prior suspicions) - Data quality issues (1854 death certificates were incomplete and inaccurate; AI would amplify these errors) - Confounders (poverty, sanitation, and water source were correlated; separating effects requires careful causal reasoning)
John Snow’s genius was not just identifying where the outbreak occurred, but understanding why and how to stop it. Modern AI excels at pattern recognition but still limited at causal reasoning and contextual understanding. The epidemiologist remains essential.
Question 5
Which of the following characteristics is MOST consistently shared by AI applications that successfully transitioned from research to real-world clinical deployment?
They use the most sophisticated and cutting-edge algorithms available
They completely replace human decision-making to eliminate errors
They solve specific, well-defined problems and augment rather than replace human expertise
They work across multiple disease areas to maximize their utility
Correct Answer: c) They solve specific, well-defined problems and augment rather than replace human expertise
Looking across 70 years of AI in healthcare, successful applications consistently share these traits:
Well-defined problems: Specific tasks with clear inputs and outputs (e.g., detect diabetic retinopathy from retinal images)
High-quality data: Large datasets with reliable labels and representative populations
Measurable outcomes: Objective evaluation of success (sensitivity, specificity, clinical impact)
Human-in-the-loop: Augment rather than replace expertise (radiologist decision support, not radiologist replacement)
Address real needs: Solve actual problems, not problems in search of a solution
Integration-friendly: Fit into existing workflows rather than demanding wholesale changes
Examples include: - Diabetic retinopathy screening (deployed in India/Thailand) - Radiology triage systems (flag urgent cases for immediate review) - Clinical decision support (suggest diagnoses, don’t prescribe treatment autonomously)
In contrast, systems that tried to replace human judgment entirely (like IBM Watson for Oncology recommending treatments) or tackle overly broad problems have largely failed to achieve sustained real-world adoption.
Question 6
The chapter identifies several “AI winters” where excitement gave way to disillusionment. Given this historical pattern, what is the MOST important lesson for public health practitioners evaluating foundation models (like GPT-4 and Med-PaLM) today?
Foundation models are just another wave of overpromise and should be ignored until proven
This time is definitely different because the technology is fundamentally more capable
Maintain skepticism about grand claims while remaining open to genuinely transformative applications, focusing on rigorous real-world validation
Wait for other organizations to deploy AI first and only adopt proven solutions
Correct Answer: c) Maintain skepticism about grand claims while remaining open to genuinely transformative applications, focusing on rigorous real-world validation
History teaches us to navigate between extremes:
Why skepticism is warranted: - Every AI wave has followed the pattern: breakthrough → overpromising → pilot studies → deployment challenges → disillusionment → gradual niche integration - We’re currently somewhere between “pilot studies” and “deployment challenges” with foundation models - Many technically impressive systems (MYCIN, Google Flu Trends, Watson for Oncology) failed to deliver real-world impact
Why This Time Is Different: - Foundation models have genuinely new capabilities: general-purpose learning, few-shot learning, multimodal understanding, rudimentary reasoning - Some applications (diabetic retinopathy screening, radiology support) have achieved real clinical deployment at scale - The convergence of data, computing power, and algorithms is unprecedented
The balanced approach: - Demand rigorous evaluation: Retrospective accuracy ≠ prospective real-world performance - Focus on deployment challenges: Integration, maintenance, equity, trust - Start with problems, not technology: Begin with public health challenges, then ask if AI helps - Center domain expertise: Work with AI developers, don’t have AI done to you - Learn from failures: MYCIN and Google Flu Trends failed for reasons worth understanding
The goal is informed engagement, neither blind enthusiasm nor reflexive dismissal.
Discussion Questions
Historical patterns: MYCIN succeeded technically but failed to deploy. Google Flu Trends published in Nature but failed in practice. What do these failures teach us about deploying AI in public health today?
Comparing eras: How is today’s deep learning fundamentally different from 1980s expert systems? What new capabilities does it enable? What old challenges remain?
Causation vs. correlation: In the 1854 cholera thought experiment, AI would have identified patterns but not mechanisms. Why is causal understanding still essential in epidemiology?
Deployment challenges: Why have so many technically successful AI systems failed to achieve widespread clinical adoption? What needs to change?
Skepticism vs. optimism: Given AI’s history of overpromise and underdelivery, how should public health practitioners balance skepticism about grand claims with openness to genuinely transformative applications?
Domain expertise: Google Flu Trends failed partly because it was built without epidemiologist input. How can public health practitioners ensure they’re at the table as AI tools are developed?
Equity implications: Historical AI systems were often developed on non-representative data. How might this pattern perpetuate or exacerbate health inequities?
This chapter was designed to be provocative, honest, and practical. AI has enormous potential in public health, but history shows that potential doesn’t automatically translate to impact. The rest of this handbook focuses on applications that work, why they work, and how to deploy them responsibly.
Next chapter: Machine Learning Fundamentals - Understanding the technical fundamentals without becoming a machine learning engineer.